Unacademy is India’s largest learning platform where millions of learners have the opportunity to access high-quality content from the best educators in the country. We aim to develop and nurture a limitless learning community that grows brilliant minds, all from the palm of your hand.
Any platform that needs to scale to serve the needs of millions of users, and provide a best-in-class experience, must incorporate complex features and functionalities. At Unacademy, we implement different, logically separate parts of this system as separate microservices.
However, this was not always the case. Like many other startups, we started with a monolith which enabled us to quickly implement new features and make deployments in an easy, simple manner. Now that we’ve scaled our platform’s offerings, as well as our user base, we have moved to microservices in order to scale separate parts of the system independently and create loose coupling between them.
While microservices solve a whole host of problems, they also tend to introduce some new problems that didn’t exist before. Among other things, you will now have to worry about:
- How to deploy these services
- How they will discover each other
- How they will communicate with each other
- How to version management will work
In this post, I will give a high-level overview of how we have solved different parts of this puzzle.
When we set out to implement microservices, we wanted the implementation to be such that any service:
- Knows how to do one thing and one thing only
- Clearly defines the API to communicate with it
- Clearly defines its dependency on other services
- Maintains its own resources, such as databases, queues, etc.
- Is developed and deployed independently
Notice that we did not mention anything about:
- What language the services should be implemented in
- What protocol they should use for communication
- Whether they should be synchronous or asynchronous
- What database, broker, cache, etc. they should use
This is one of the advantages of microservices. The implementer can choose a toolset that is the best fit for the problem that he/she is trying to solve. Hence we have services written in Python, Go, Java, NodeJS, etc. which use a wide variety of technologies such as MySQL, DynamoDB, Redshift, SQS, SNS, Kinesis, X-Ray, etc.
How Feeds Work
To demonstrate the interaction between different services, let’s look at how feeds are served to users.
When the users are on their home screens, they see a feed of lessons and posts. The feed is different for different users and is generated using machine learning algorithms. Therefore, a post that might show on the top for one user might show up much lower for another. The ranking of these items is generated for all users every six hours. Hence, if a user opens the app at every six-hour interval, he/she is going to see different items in the feed. But we don’t want our users to see stale feed if they are looking at their feed at an interval shorter than six hours. To tackle this, we serve the current version of the feed to the user when an API request comes, but we also immediately start computing the new feed. After a few seconds, when the new feed is ready, we publish a message to the client asking it to fetch the feed again.
Now that we know the high-level functionality, let’s look at how this works.
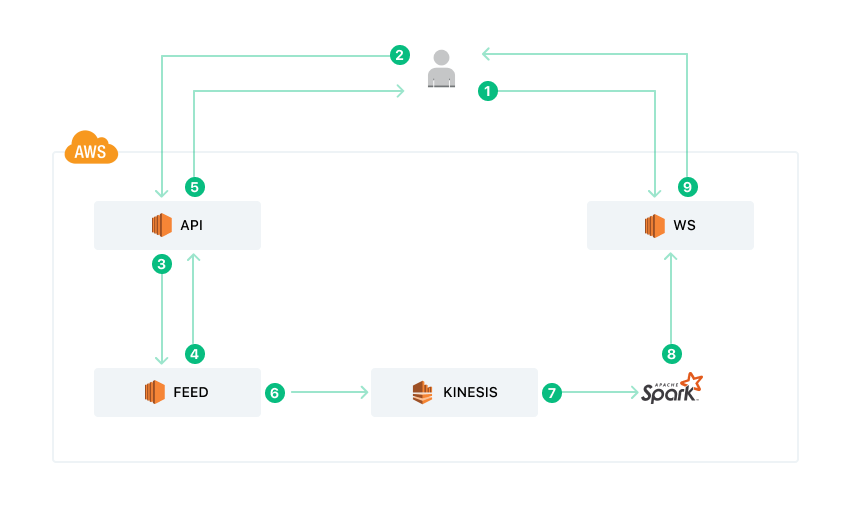
Various components of this system are:
- API server: It is our main service that hosts the various APIs. It is implemented in Python.
- Feed service: This service handles all the logic related to feeds. It is implemented in Golang.
- Kinesis: It is the AWS-managed service for real-time streaming data.
- Recommendation System: It is a Spark Streaming job that implements the ML algorithms based on which feed items are ranked.
- Websocket Server: It is the WebSocket server that is used for real-time communication and server-side push. It is written in Golang.
The flow of requests is as follows:
- The client connects to the Websocket server and subscribes to feeds.
- It then makes a request to the API server asking for the feeds to show to the user.
- The API server proxies this request to the Feed service.
- The Feed Service responds with the current version of the feed it has in its database.
- The API server does some enrichment and sends the response back to the user.
- The Feed Service also sends an event to Kinesis that a new feed needs to be generated for this user.
- The Recommendation System reads the event and computes the new feed.
- The Recommendation System publishes a message to the Websocket server telling it that a new feed is available for the user.
- The websocket server sends the message to the client asking it to fetch the feed again.
- The client again makes an API request to the API server.
- The API server proxies the request to the Feed service.
- The Feed Service responds with the latest feed.
- The API server enriches the response and sends it back to the client, thereby delivering the recently computed feed.
The above description leaves out some of the critical details like
- Is there a single instance of various services or many?
- If there are many, who decides how many?
- How do the services communicate?
- How is load balancing done among them?
- How are the various instances discovered?
Let’s try and answer these questions. Here is a more detailed picture that will give more insights into our infrastructure.
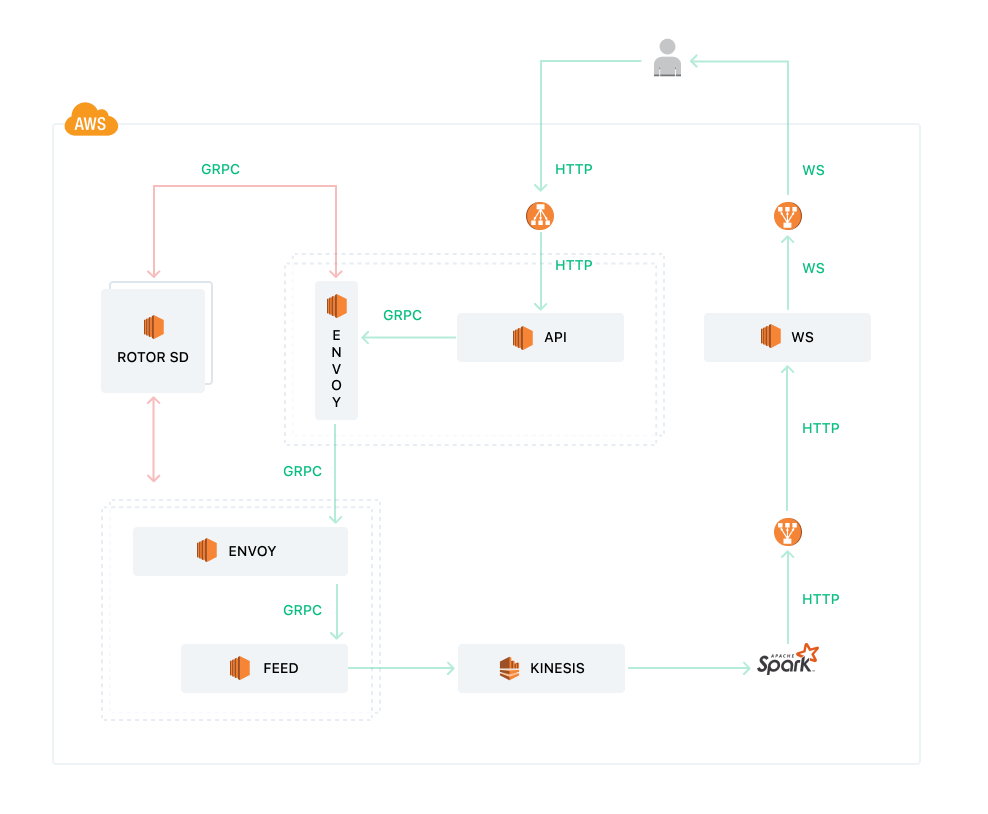
High Availability and Autoscaling
Since our services run on AWS EC2, we use the autoscaling features provided by AWS to launch or kill services based on load. To do this, our deployment setup creates an AMI which is used to create an autoscaling group. Whenever new instances have to be launched they use this AMI which already has our service and other agents installed. We develop our services in a manner such that they can always be horizontally scaled. And for high availability, we have a minimum of two instances of all our services running. Hence, in our autoscaling group configuration, we specify the minimum instance count as 2. To actually do autoscaling, AWS requires alarms and policies. For example, we might want to launch a new instance of Feed Service when the average number of requests per instance is more than 200 per second. When this happens, an alarm is raised which is looked at by autoscaling and a new instance gets launched, thereby reducing the average number of requests per instance. These alarms rely on metrics that are published to AWS Cloudwatch. Each of our services publishes a wide variety of metrics that can be used both for autoscaling and for judging the performance of the service. Our deployment scripts enable the developers to provide simple configurations based on which the alarms and policies get automatically created at the time of deployment. The developers can choose to autoscale their services based on CPU usage, average request rate, request latencies, SQS queue length, etc.
Service to Service Communication
Any service that is exposed externally has AWS ALB (Application Load Balancer) in front of it. Hence, the clients only need to know the DNS domain for the service to be able to communicate with it. In the case of our Feed System, API Server and Websocket Service are the only services that are exposed to the client.
For service-to-service communication, we use a sidecar proxy. A sidecar is a separate process that runs alongside your service and acts as a proxy for all incoming and outgoing requests. The sidecar can handle some of the common functionalities such as to request logging, metrics, routing, load balancing, health checks, circuit breaking, protocol conversion, etc. It is advantageous to have these functionalities implemented outside of our own application so that our applications only need to deal with our application logic. So if we look at communication between two services, it looks like the following.
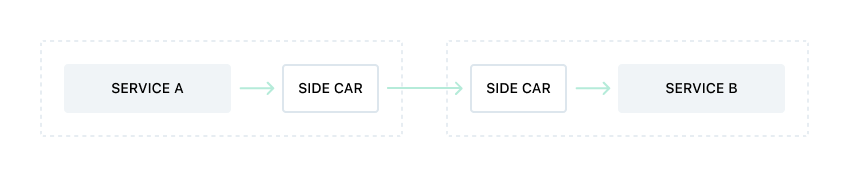
Service-to-Service communication using Sidecar proxy
The communication protocol that we want to use needs to be supported by the sidecar proxy. We use HTTP, HTTP/2, and gRPC for our request/response kind of communication. We use Envoy which has first-class support for all of these. Envoy also emits a lot of metrics that can be pushed to your favorite backend. It can also do health checks and load balancing, which will be discussed in the next section. Since the services are only talking to the sidecar proxy on there localhost, they don’t need to know where the remote service is. The service only needs to specify which remote service it needs to communicate with. We do that by setting the Host header for an HTTP request, or the Authority header for an HTTP/2 request. gRPC uses HTTP/2 underneath and hence uses the Authority header too. The responsibility of knowing where the remote services now fall on to the sidecar.
We prefer the use of gRPC for communication because of the type of safety it provides and for the performance benefit, it provides by establishing a long-lived connection on which multiple requests are multiplexed. Since the gRPC clients are auto-generated, we get the benefit of type safety across languages without having to write clients manually. The protobuf used by gRPC also serves as well documented and versioned contracts that are exposed by a service.
For asynchronous communication, we generally use SQS. Services put messages into a particular queue which is read by multiple instances of the consumer service.
Service Discovery, Load Balancing, and Health Checks
To be able to communicate with one of the instances of a service, we need to know the IP address and port of the machine where the service is running. Also, since our services are part of autoscaling, the instances come and go and we cannot maintain a static list of IP addresses where a particular service is hosted. What is needed is dynamic service discovery.
In the case of externally exposed services, the current list of instances of the service is maintained by AWS. Any time a new instance is launched by autoscaling, it is added to the target group for that autoscaling group. Similarly, the instances are removed from the target group when they are terminated. ALB routes requests to all the instances in the target group. Hence, service discovery is already solved for us.
For internal services, we do not use ALB. Therefore we somehow need to know of all the machines that are hosting a particular service at any moment in time. Once we have that information, we need to tell Envoy about it so that it can route requests to those services. Envoy does not know how to do service discovery. It relies on external services to provide it the requisite information. It exposes a gRPC contract which any service can implement and Envoy will ask that service to tell it the details of any service cluster. While one can definitely write a service discovery implementation on their own, there is already an excellent implementation available called Rotor. The rotor can use multiple methodologies to do service discovery. What we use is their support to scan the EC2 instances in our AWS account and group instances based on tags. Hence, if you have three instances that have tags saying that they host Feed Service, then Rotor is going to group them and let Envoy know that any of the requests to Feed Service must go to one of these instances.
Envoy takes care of load balancing across these services. There are different load balancing policies that can be configured for Envoy. For load balancing, the knowledge of where the services reside is not enough. We also need to know if the services are healthy. For example, while Feed Service may be running on three machines, it might be hung on one of the machines and hence not responding to requests. We do not want Envoy to send requests to that instance even though Rotor reports that the service is running there. For this, Envoy supports health checks on services and it only routes traffic to instances that are healthy.
Summary
In this post, we take a high-level look at how microservices are developed at Unacademy. We have developed generic libraries and deployment scripts to complement the design choices we have made. These enable the developers to get their applications up and running in no time. The move to microservices has helped us tackle most of the problems we were trying to solve. These are our first steps in this direction and we anticipate a lot more experimentation and development on this front.
