Unacademy is India’s largest learning platform. At the heart of what we do is building a world-class product that creates tremendous value for all our users. Creativity, innovation, and competency. These are three pillars that are integral to the foundation of our teams at Unacademy.
Due to a great product-market fit and people realizing the value and benefits of our platform, our traffic skyrocketed to 80k RPM, a 3x increase. With the amount of growth we have seen, the surge in the AWS bill was inevitable. With time we realized that we were leaking money and it was time to keep our bill in check.
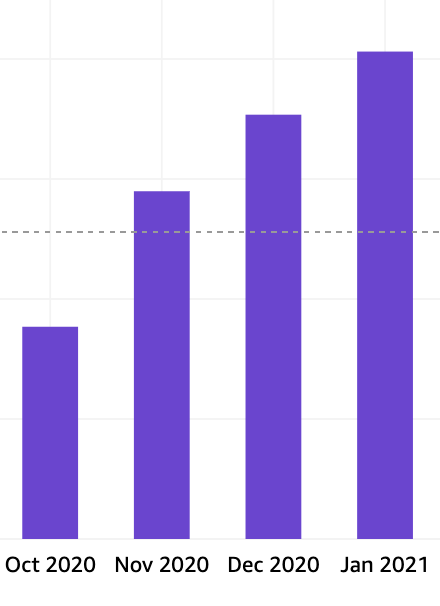
Since October 2020, our AWS bill grew 15% MoM and it is very evident from the chart below; and hence in February 2021, we picked up the mammoth task to reduce the AWS bill.
Constraints
We liked the way Damien Pacaud put it!
“Make it work, make it right, make it fast” … and then cost-efficient.
While optimizing the AWS bills we followed these self-imposed rules:
- We are a 100+ engineers team and the features roll out at a brisk rate; cost optimization exercise should not slow down development and product releases.
- Availability, robustness, and scalability of our platform are of at most priority and will not be traded for few bucks of reduction.
- Revamping an existing microservice is not an option.
Understanding the cost
Addressing the elephant in the room Where is the money going? For this, we needed to have a better understanding of our AWS cost and usage. Furthermore, create a transparent accountability process.
We laid the foundation by tagging all the resources and configuring User-Defined Cost Allocation Tags in AWS. This had multiple benefits.
- This facilitated cost attribution/accountability to the team and the services.
- We have around
10,000 resourceson AWS and this helped us identify all the obsolete and stale resources. - We leveraged this process to deeply understand our complete AWS resource inventory and its relationship with one another.
We invested in the CUDOS Quicksight dashboard - the most comprehensive source of AWS billing data available. We found it pretty useful as it provides the cost and usage report. We used this dashboard to capture a bird's-eye view of our infrastructure cost. We analyzed the cost trends, summaries, and recommendations provided for each service to compile action items.
Other useful sources for billing data are AWS Cost Explorer and Billing & Cost Management Dashboard. Note that AWS takes around 2 days to populate the data in these dashboards.
We followed a metric-driven methodology to achieve our goal.
- Analyzed: Inspected the CUDOS dashboard and narrow down the highest billed AWS services.
- Planned: Studied and discussed the remediation plan.
- Implemented: Made changes to the resources.

What did we do?
The golden rule we followed
Terminate the obsolete resources and right-size the rest of them
We analyzed the critical metrics of the resources to identify over-provisioned resources and decided whether to downscale or not. We made sure that the downscaling of resources was done incrementally and was monitored continuously. This way we decreased the likelihood of having any downtime or service interruptions.
Trusted Advisor
Trusted Advisor is an AWS-managed service that helps better security posture and performance as well as reduces AWS costs. We saved money by following AWS Trusted Advisor's recommendations to identify and eliminate all the idle/under-utilised resources such as EC2, ELB, ElastiCache, Redshift, RDS, etc.
EC2
We leveraged AWS Compute Optimizer to identify over-provisioned EC2 instances(compute) and downsized those. We also developed a service to shut down non-production serving machines during off-hours.
We upgraded our instance fleet to the latest generation of instance type as it has a better cost to performance ratio. Comparing the benchmark report of c4.large and c5.large shows that the new generation machine is 15% less costly and 11% more powerful.
We terminated unused EC2 instances instead of stopping. When the instances are stopped, AWS stops charging us for the instance but the EBS cost is still billed.
RDS
To right-sized RDS we analyzed CloudWatch metrics for RDS. Metrics like CPUUtilization, FreeableMemory, and ReadIOPS help understand the RDS performance. It is recommended to enable Performance Insights and Enhanced Monitoring for more data points. Downscale the instance step by step and monitor the instance for few days.
RDS pricing model also considers IOPS. Hence, it's important to right-size the storage as well. Low IOPS will throttle RDS performance and high IOPS will incur unnecessary costs. Cloudwatch metrics like ReadIOPS, WriteIOPS, ReadLatency, and WriteLatency helped us make wise downscale decisions.
To further improve resource utilization and ROI, we piggybacked qualified RDS to one and used them by creating databases for each one.
We also reviewed our RDS backup lifecycle policy and deleted manually and automatically created DB backup snapshots. Unlike automatic backups which are deleted according to their retention policy, manual backups have to be deleted manually. To prevent this in the future, we developed a cron job to delete manual backups older than 7 days.
ElastiCache(Redis)
Similar to RDS we first right-sized the instances by analyzing database memory utilization and Engine CPU.
A Redis instance supports multiple logical databases, which is very similar to the concept in SQL databases. These databases are effectively isolated from the other databases in the Redis instance. Redis supports 16 databases numbered from 0 to 15, and 0 being the default database.
We piggybacked eligible Redis instances to one and consume them by creating databases for each service, improving overall resource utilization. We checked the performance metrics of the non-critical low volume Redis instances to consider them for piggybacking.
S3
The major portion of S3 cost is due to storage. To reduce data stored in hot expensive S3 storage class we defined S3 lifecycle rules to:
- Transition objects to cold storage as per their historic retrieval pattern.
- Delete incomplete failed multipart uploads on each of our S3 buckets.
- Transition older S3 version to Glacier. As per few specific use cases, we added a rule to delete the older version altogether.
Before moving objects to a cost-effective storage tier, consider the access pattern for the data and the object size. For example, S3 stores an additional 32KB of data in the “Standard” storage class, for each object stored in Glacier. Hence, if we store objects with a size less than 32KB, the total cost will be higher than simply storing the data in the Standard storage class.
To address the data transfer charges we enabled an S3 VPC endpoint to transfer data between buckets and EC2 instances. This enforces data exchange through VPC internal routes and AWS won't charge it as public data transfer.
EBS
We deleted obsolete EBS volumes in the available state and stale EBS snapshots. We are planning to test the gp3 volume type in place of the gp2 volumes. gp3 volume is a new type of SSD EBS volume that is 20% cheaper than gp2 volume types. And unlike gp2 volumes, their performance is independent of storage capacity.
We leveraged Trusted Advisor to identify oversized volumes and took action to remove unused capacity and reduce cost. Note that increasing the EBS volume is possible but AWS won't allow you to decrease it. So, start with a smaller volume size and incrementally bum up the storage size.
Keep in mind S3 storage cost is half of that of EBS. S3 can be a cheaper alternative to backup the EC2 data that is not going to be frequently retrieved and the read latency is not a concern. For throughput-intensive workloads, EBS is the best bet.
Cloudwatch
The significant contributor to the Cloudwatch service is the Cloudwatch log group. We decreased the cost by first reducing the log event size. We also tuned the retention period of CloudWatch log groups or removed the log stream altogether if logs are not analyzed.
We have VPC flow logs enabled to analyze and monitor network issues. We had configured both S3 and Cloudwatch logs to store these logs, costing us twice the amount. We reconfigured this to export logs to S3 and then analyzed on Athena when required.
We identified and deleted a bunch of alarms with Actions as Configuration not verified or State as Insufficient data for a long time.
Dynamodb
ConsumedReadCapacityUnits and ConsumedWriteCapacityUnits are the cost determining metrics and also the ones that can be easily tuned to boost savings. We transitioned to the on-demand capacity model as it serves almost all types of requirements. We have provisioned capacity on tables where traffic is busty.
We reserved DynamoDB provisioned capacity as it offers significant savings over the standard price. This works like the usual reservation plan, where reserved capacity is charged at a discount, and any capacity consumed above the reserved capacity would be billed as a standard charge.
Deleting stale records from the table also saved a few bucks.
Autoscaling group
We reviewed and modified the EC2 AutoScaling Groups configuration to add instances conservatively. Also, reviewed the minimum number of the instance to server traffic but with smaller fleet size.
We ensured to leverage the latest generation instance type and right-sized them as per the use case. Also made a point to use the apt mix of on-demand, spot instances and reserved instances to enhance ROI without compromising on availability and scale.
At Unacademy, we love Spot instances. It has the potential to reduce the cost by 90%. The only downside being AWS can terminate these spot instances anytime. Use spot only for fault-tolerant and resilient workloads.
To keep the costs in check we used instance scheduled scaling to scaledown during off-peak hours.
Kubernetes
We are in transition from a monolith to microservices and all these services would be hosted on Kubernetes. Keeping the availability and cost in mind we designed a brand new EKS cluster. We moved existing services running on bare EC2 instances and old Kubernetes to the new cluster.
Having adopted Kubernetes, we were able to leverage the Cluster Autoscaler to automatically adjusts the number of nodes in the cluster. We also reviewed and tuned HPA policies, minReplicas and maxReplicas parameters to effectively scale the services. All these bumped up our resource utilization and scalability.
We also installed Kubecost - cost monitoring and capacity management solution. It provides beautiful dashboards for real-time cost visibility into our Kubernetes cluster. It also helps locate unused volumes, over-provisioned replicas, and pod right-sizing.
Elasticsearch
We reduced the size of the Elasticsearch cluster based on CloudWatch metrics like CPU utilization, JVM pressure and memory usage. We are also planning to have gp3 EBS volumes for our storage layer in the Elasticsearch clusters.
Buy Reservation plan
After we right-sized all critical resources, we reserved them by buying no upfront reservation plan for one year term. We reserved only 60-70% of our total capacity giving us some room for error.
Amazon RDS Reserved Instances provide size flexibility for the instances with the same instance family, region and database engine. With size flexibility, within a DB instance family, the Reserved discount gets applied to instances of that same family, regardless of size.
We bought an enterprise compute savings plan for all our compute layers. We also bought a Sagemaker savings plan for all our eligible Notebooks and ML instance usage. Please refer to this article and know more about AWS Savings Plan.
Conclusion
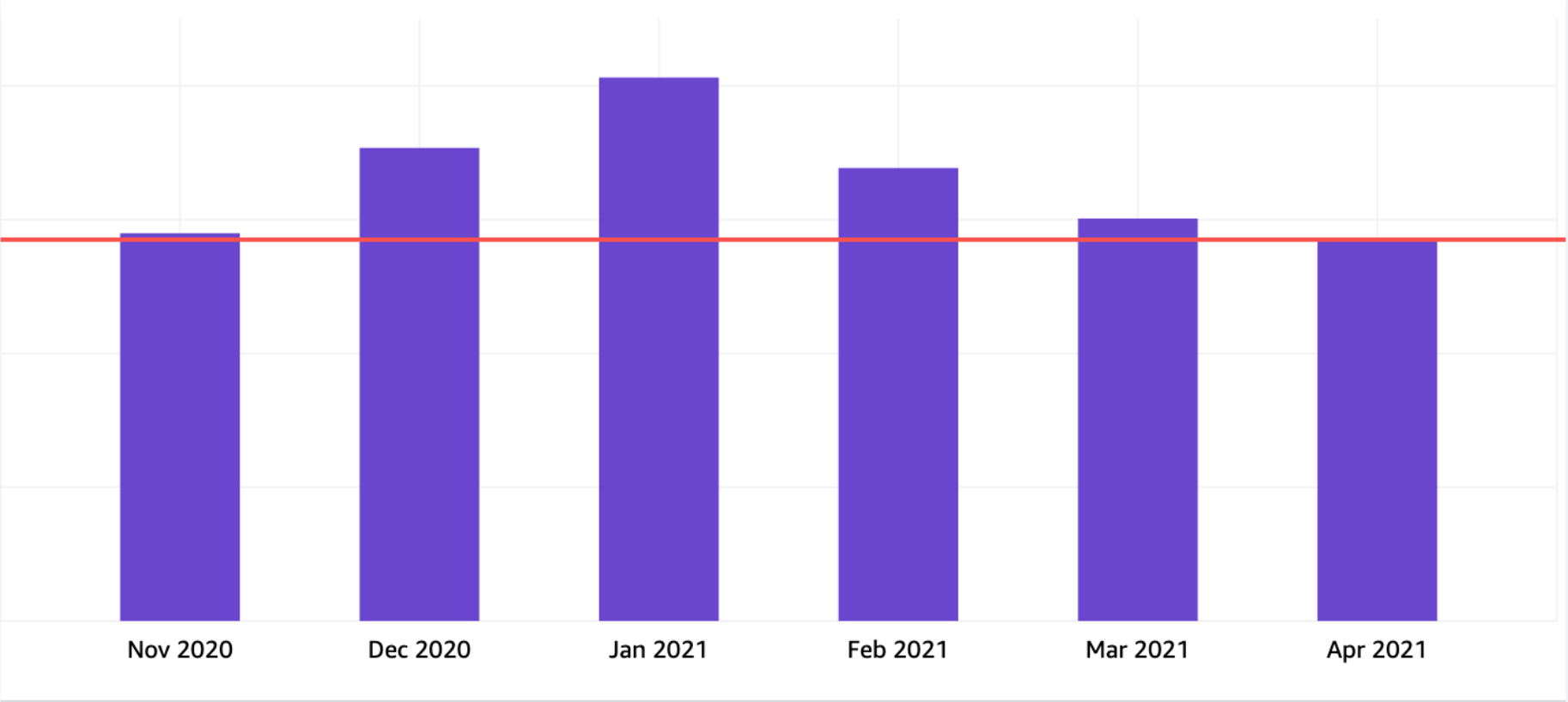
We were able to reduce our bill by 43% of the AWS forecasted amount for the month.
We realized this is not a one-time effort but a regular routine. We also learned about AWS pricing models for various services and best practices around cost optimization without sacrificing availability and resiliency.
To prevent leaking costs in the future, the infrastructure team works closely with the service owners while designing the service architecture to ensure the cost is optimized. The infrastructure team runs periodic scans to identify obsolete or over-provisioned resources and terminate those. We also monitor the cost and usage trends on our CUDOS dashboard to detect and remediate any anomaly.
