Search is one of the most important features for an open education platform like Unacademy, and as of 25th February 2019 has 85K courses and 857K lessons spanning over 85 categories and taught by 18K educators, and it is a simple looking search bar that is responsible for the discovery of all of this content to our users.
16% of all lessons watched are attributed to Search, which means 1 in every 6 lessons that are watched, it was Search that has helped users land on it and learn something new and amazing.
In this blog post, I would take you on a tour that explains what we do after you tap on that nice-looking “Search Bar”.
Deciding what we wanted
The one requirement from every search product is its Relevance, but apart from that, the other primary requirement that we had was the need for a system that is simple and extensible, yet powerful enough to support all sorts of complex dynamics of a full-fledged search system.
Apart from the above features, one thing that we wanted our system to have, was the ability to be AB Testing and experimentation friendly because we, at Unacademy, like to run fast without breaking things. Additionally, we had to ensure that our platform is future-ready and could be extended with ease at any point in time.
Building Blocks
The following diagram shows a simplified version of our architecture
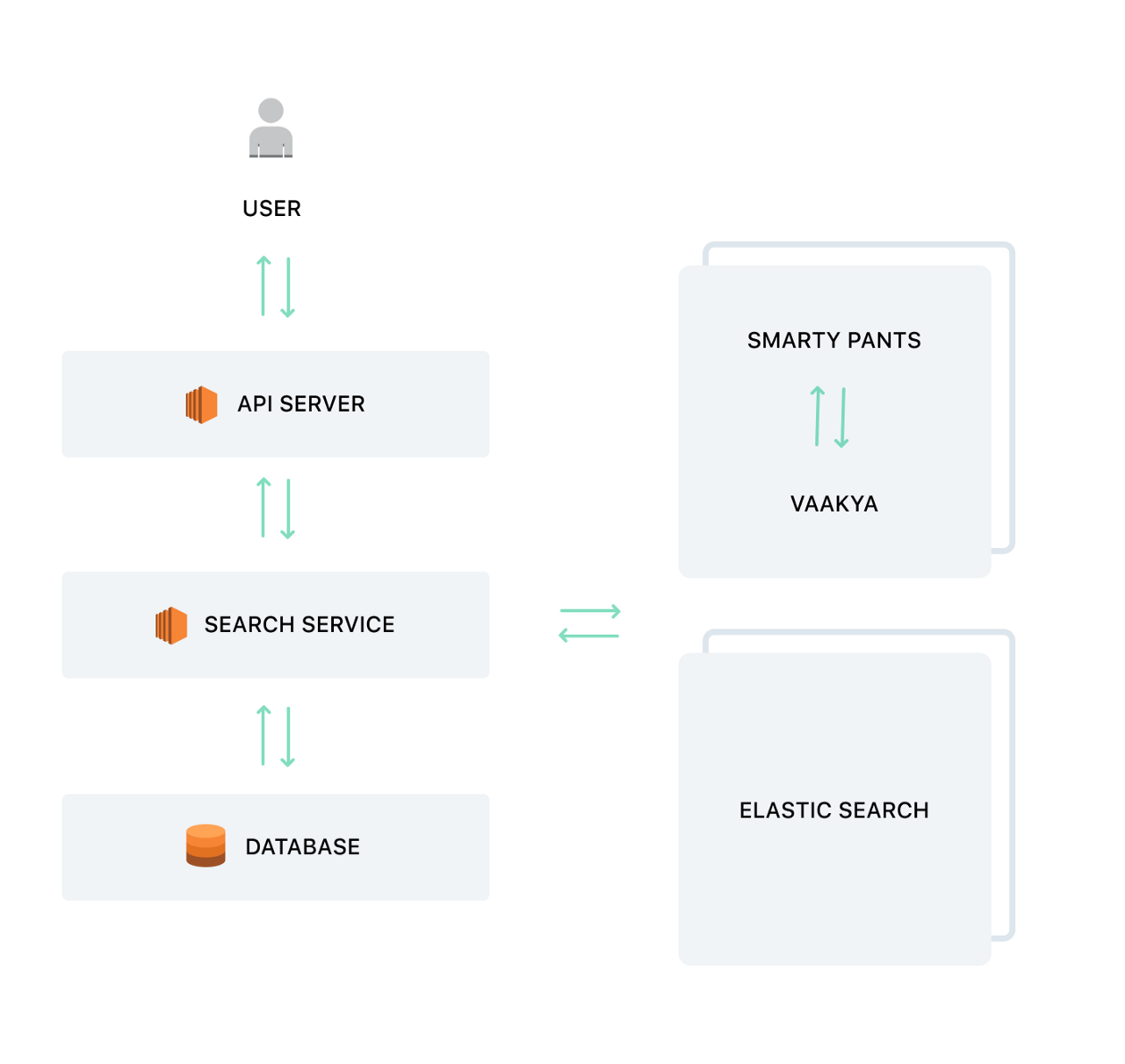
User and API Server
Once the end-user initiates the search, the request reaches our API server. The request handler then performs a basic validation check on the query and the applied filters and then forwards it to the search service, where all the magic happens.
Search Service
The search service is responsible for managing all the configurations and query templates, creating and firing Elasticsearch queries, all the results, plugging in non-static information into response, making final minute adjustments to results, and finally sending a response back to the primary API server.
Elasticsearch
The search at Unacademy is powered by Elasticsearch which is our primary search engine. Elasticsearch has a very vast range of performant and elegant APIs that meet our needs. So, it is the responsibility of the search service to create and translate the user search query into a valid Elasticsearch query and then we let Elasticsearch do its magic and give us back the results.
Smartypants
Smartypants is our in-house service that, given a query returns a set of meta information and some “smart” suggestions about the query, and hence the name.
Vaakya
Vaakya is our in-house String processing library which is heavily optimized for all String-related operations. It also holds the Unacademy vocabulary, word segmentation algorithm, list of synonyms, and list of stopwords.
Platform Capabilities
Tiered Search
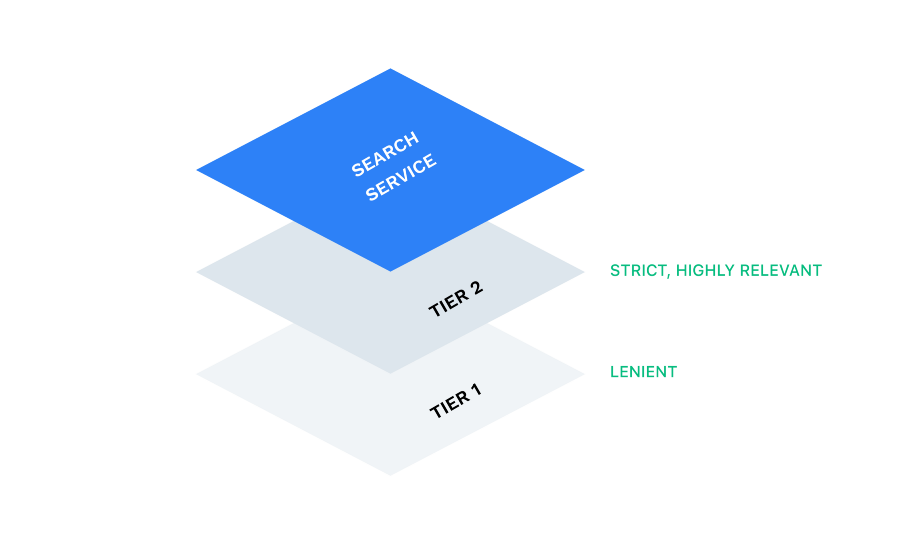
Our search is tiered which means we make multiple calls for a search query and then serve the results. The first call goes for much stricter constraints and if we get no results from it then we make the same call but with many lenient constraints.
This way we ensure that we serve the most relevant content if we are able to find it for a query and in case we do not find anything that is super relevant then we dial down the constraints and make a search again. This time we get results that are kind of relevant but not to a greater degree.
Query templates
In order to communicate with Elasticsearch, we need to write a JSON query that is understandable by the engine. Since there are thousands of operations and customization that are provided by Elasticsearch, we have defined a few query templates that suit most of our use cases.
These templates enable us to cater to a wide range of user requirements by defining templates for each type of search and thus giving us a clear path for continuously improving the search relevance and experience.
Dynamic Query Configuration
The Query Templates explained above, have a lot of placeholders that need to be filled so that it forms a valid Elasticsearch query. These placeholders are filled using the configurations associated with each field in an Elasticsearch index.
The configurations are specific to the type of content the field holds and are driven by DB and hence can be changed on the fly. Thus we can define the fields that we want to search, rank, and sort on; define how we want to search and associate simple integer weights to each field.
Query Configurations per Query Type
The platform also supports Query Types which means we could club a set of similar queries and assign a type to it, and then associate a configuration to this type. This way we fine-tune how each type of search query should be treated by our engine.
For example, the queries that are time-bound, like Daily News Analysis, are assigned a type of High Recency. The configuration associated with this type gives a higher boost to the course publish date and time, this way we ensure that the content that is recent is ranked higher for these queries without meddling with other general queries.
Experimentation
At Unacademy we like to run really fast and especially with Search we like to run experiments and measure the impact of our change as there is no one clear Quantitative way with which we can tell beforehand that we have improved things, and hence experimentation support was a must for us.
With configurations and support for Query Types, the AB experiments are a breeze for us. We club different configurations under one group and fire queries for the group and return the results. To put things into perspective, in the last few months, we have launched an AB experiment every two weeks.
Search at Unacademy HQ thrives to improve the user experience by serving the most relevant content for user queries, and while we have crossed a lot of hurdles, there’s a long way for us to go.
